
Pythonの403エラーの原因

PythonのRequestsで403(HTTP Forbidden)エラーになったときの対応方法。
スクレイピングのスクリプトを動かしていて、ウェブサイトにアクセスしたときに403になるケースがあるようです。
原因はいくつかあって、以下のようなケースあり。
- ブラウザ以外のアクセスを拒否するようにウェブサイト側が設定している
- 間隔を開けずにスクリプト等から連続アクセスした
- アクセス時にID、パスワードが必要で、どちらかを間違えている
- アクセス先のURLを間違えている
特殊な例として、社内ネットワーク上のサーバに、Active Directory管理下ではない端末からアクセスしようとした…というケースもあるようです。
Pythonの403対策(urlopenやrequests)

Pythonのスクリプト内からウェブにアクセスしようとして403が出る場合の対策。ブラウザ以外のアクセスを拒否するという設定になっている場合、アクセス時の「ユーザーエージェント」という情報を見ています。
ブラウザのユーザーエージェントは、以下のページで確認できます。
> IPアドレスとユーザーエージェントの確認(testpage.jp)
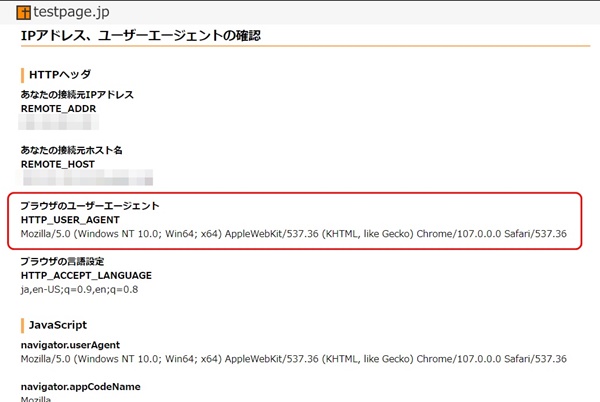
「ブラウザのユーザーエージェント」というところに表示されます。ブラウザはchromeを使用。具体的には、ユーザーエージェント(HTTP_USER_AGENT)は以下の文字列になっていました。
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36
requestを使って、google.comにアクセスしてみましょう。ユーザーエージェントとは、上記の文字列に偽装します。
偽装というと、なにかペナルティがありそう…と思ってしまいますが、間隔をおかずに連続でリクエストを送りまくったりしない限りは大丈夫だと思います。
なんとなくの暗黙のルール的に、スクリプトでウェブページに自動アクセスする場合は、1秒以上間隔をあけること、というのがあります。1秒というのは肌感覚的なものです。
APIなどで、明確にリクエスト間隔が決まっている場合は、そちらに従ってください。
$ cat reqtest.py
#!/usr/bin/python3
import urllib.request
# リクエスト情報を作成
req = urllib.request.Request('http://google.com' )
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36' )
# リクエスト情報に基づき、google.comをオープン、返ってきた文字列を表示する
with urllib.request.urlopen( req ) as res:
text = res.read().decode('utf-8')
print( text )
実行するとこうなります。google.comのHTMLデータを取得できました。
$ ./reqtest.py
<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="ja"><head><meta charset="UTF-8"><meta content="origin" name="referrer"><meta content="/images/branding/googleg/1x/googleg_standard_color_128dp.png" itemprop="image"><link href="/manifest?pwa=webhp" crossorigin="use-credentials" rel="manifest"><title>Google</title><script nonce="HoKSBzlN6m3QLOUNWbb3sg">(function(){window.google={kEI:'sPKBY8j3McapoAT04pHQDg',kEXPI:'31',kBL:'-1VY'};google.sn='webhp';google.kHL='ja';})();(function(){
:
:
HTMLから必要データを抜き出す(スクレイピング)するには、Beautiful Soupなどのモジュールを使うと楽です。
関連)Beautiful Soupドキュメント — BeautifulSoup Document 3.0 ドキュメント
ちなみに、間隔をあけずにリクエストを繰り返すと、Googleの場合はHTTP 403エラーが出るようになります。1~2時間で解除されるぽいです。
Pythonの403エラー対策まとめ

- Pythonでウェブページにアクセスして403エラーが出る場合、ユーザエージェント文字列が原因のケースがある
- ユーザエージェントをブラウザと同じに偽装すると、アクセスできるケースが多い
- スクリプトで間隔をおかずに連続リクエストをすると、何をやっても403エラーになることがあるので注意